
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
Tags
- visualizing
- pandas
- data analyze
- 크롤링
- TypeScript
- matplotlib
- opencv
- instance
- 프로젝트
- javascript
- analyzing
- webcrawling
- Scrum
- AWS
- Agile
- 다나와
- keras
- tensorflow
- Method
- data
- DANAWA
- python
- adaptive life cycle
- 애자일
- Crawling
- 자바스크립트
- Project
- algorithm
- ECS
- angular
Archives
- Today
- Total
LiJell's 성장기
__07.data_analyzing_visualizing_tourist_data (한국 관광객 추이 2편) 본문
Bigdata/Web Crawling
__07.data_analyzing_visualizing_tourist_data (한국 관광객 추이 2편)
All_is_LiJell 2022. 1. 17. 18:25반응형
- 한국 관광객 추이 1편 크롤링/전처리: https://lime-jelly.tistory.com/43
__06.data_analyzing_tourist_data (한국 관광객 추이 1편)
한국 관광객 추이 2편 시각화: https://lime-jelly.tistory.com/46 __07.data_analyzing_visualizing_tourist_data 이전 과정은 아래를 참고 data 변환: https://lime-jelly.tistory.com/43 7. tourist data visua..
lime-jelly.tistory.com
7. tourist data visualizing (관광객 데이터 시각화)
7.1. 시계열 그래프 그리기
import pandas as pd
import numpy as np
from pandas import Series, DataFrame
import matplotlib.pyplot as plt
from matplotlib import rc, font_manager
import seaborn as sns- 한글 지원
path = 'c:/Windows/Fonts/malgun.ttf'
font_name = font_manager.FontProperties(fname = path).get_name()
# font_name
rc('font', family = font_name)7.1.1. 데이터 불러오기
df = pd.read_excel('./files/kto_total.xlsx')
df.head()
'''
국적 관광 상용 공용 유학/연수 기타 계 기준년월 대륙 관광객비율(%) 전체비율(%)
0 일본 202825 1750 89 549 3971 209184 2010-01 아시아 96.96 50.602515
1 중국 40425 11930 55 2751 36091 91252 2010-01 아시아 44.30 10.085575
2 대만 35788 41 17 37 516 36399 2010-01 아시아 98.32 8.928696
3 미국 26943 1195 2145 135 12647 43065 2010-01 아메리카 62.56 6.721970
4 홍콩 13874 55 0 21 595 14545 2010-01 아시아 95.39 3.461404
'''7.1.2. 중국 데이터 필터링하기
df_filter = df[df['국적']== '중국']
df_filter
'''
국적 관광 상용 공용 유학/연수 기타 계 기준년월 대륙 관광객비율(%) 전체비율(%)
1 중국 40425 11930 55 2751 36091 91252 2010-01 아시아 44.30 10.085575
61 중국 60590 7907 68 29546 42460 140571 2010-02 아시아 43.10 13.569168
121 중국 50330 13549 174 14924 62480 141457 2010-03 아시아 35.58 9.227345
181 중국 84252 13306 212 2199 47711 147680 2010-04 아시아 57.05 15.507483
241 중국 89056 12325 360 2931 49394 154066 2010-05 아시아 57.80 16.952005
... ... ... ... ... ... ... ... ... ... ... ...
7200 중국 393336 2813 99 10433 75000 481681 2020-01 아시아 81.66 38.169469
7262 중국 49520 715 11 20753 33087 104086 2020-02 아시아 47.58 9.825826
7321 중국 5040 115 2 7388 4050 16595 2020-03 아시아 30.37 16.000508
7382 중국 522 71 0 1112 2230 3935 2020-04 아시아 13.27 10.161573
7445 중국 179 70 2 1189 3684 5124 2020-05 아시아 3.49 2.928186
125 rows × 11 columns
'''7.1.3. 데이터 시각화하기
plt.figure(figsize = (12, 6))
plt.plot(df_filter['기준년월'], df_filter['관광'])
plt.title('중국관광객 추이')
plt.xlabel('기준년월')
plt.ylabel('관광객 수')
plt.xticks(['2010-01', '2011-01', '2012-01', '2013-01', '2014-01', '2015-01', '2016-01', '2017-01', '2018-01', '2019-01', '2020-01'])
plt.show()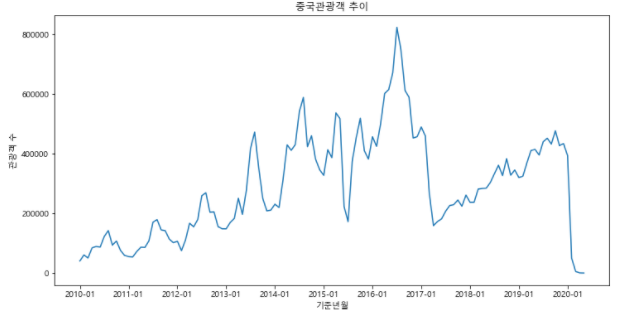
7.1.4. 외국인 관광객 상위 5개 국가의 리스트 만들기
cntry_list = ['중국','일본','대만','미국','홍콩']7.1.5. 반복문으로 시각화하기
for cntry in cntry_list:
condition = df['국적'] == cntry
df_filter = df[condition]
plt.figure(figsize = (12, 4))
plt.plot(df_filter['기준년월'], df_filter['관광'])
plt.title('{}관광객 추이'.format(cntry))
plt.xlabel('기준년월')
plt.ylabel('관광객 수')
plt.xticks(['2010-01', '2011-01', '2012-01', '2013-01', '2014-01', '2015-01', '2016-01', '2017-01', '2018-01', '2019-01', '2020-01'])
plt.show()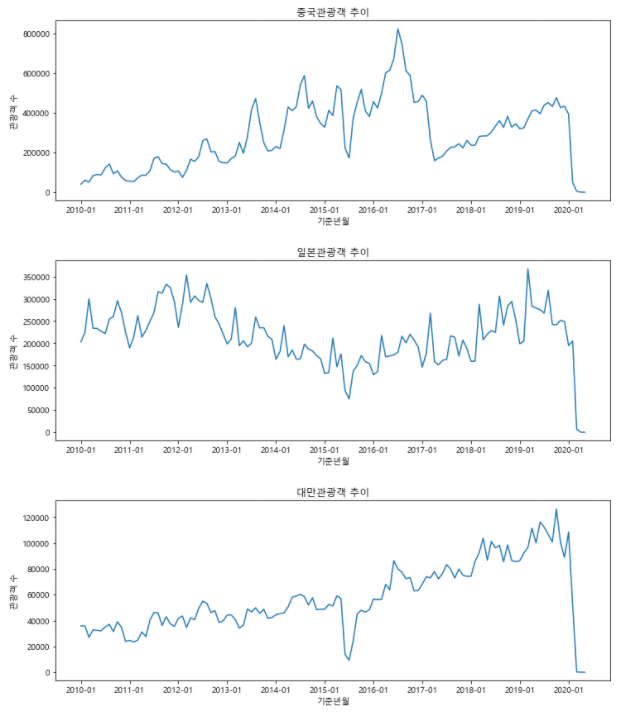
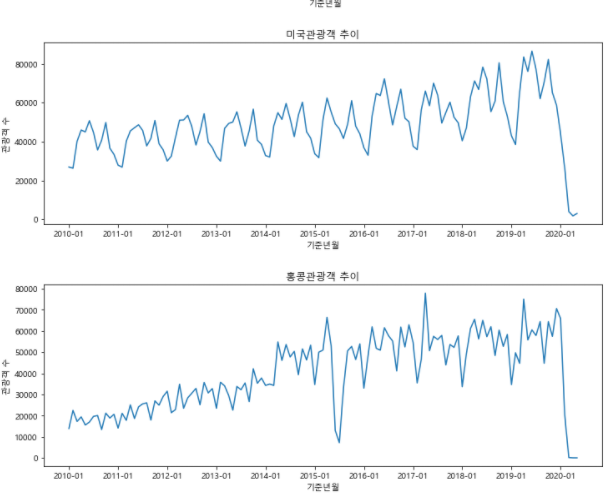
7.2. 히트맵 그래프 그리기
- 정보 확인
df.head()
'''
국적 관광 상용 공용 유학/연수 기타 계 기준년월 대륙 관광객비율(%) 전체비율(%)
0 일본 202825 1750 89 549 3971 209184 2010-01 아시아 96.96 50.602515
1 중국 40425 11930 55 2751 36091 91252 2010-01 아시아 44.30 10.085575
2 대만 35788 41 17 37 516 36399 2010-01 아시아 98.32 8.928696
3 미국 26943 1195 2145 135 12647 43065 2010-01 아메리카 62.56 6.721970
4 홍콩 13874 55 0 21 595 14545 2010-01 아시아 95.39 3.461404
'''7.2.1 년도, 월 컬럼 추가하기
df['년도'] = df['기준년월'].str.slice(0,4)
df['월'] = df['기준년월'].str.slice(5,7)7.2.2 중국 필터링하기
condition = df['국적'] == '중국'
df_filter = df[condition]
df_filter.head()
'''
국적 관광 상용 공용 유학/연수 기타 계 기준년월 대륙 관광객비율(%) 전체비율(%) 년도 월
1 중국 40425 11930 55 2751 36091 91252 2010-01 아시아 44.30 10.085575 2010 01
61 중국 60590 7907 68 29546 42460 140571 2010-02 아시아 43.10 13.569168 2010 02
121 중국 50330 13549 174 14924 62480 141457 2010-03 아시아 35.58 9.227345 2010 03
181 중국 84252 13306 212 2199 47711 147680 2010-04 아시아 57.05 15.507483 2010 04
241 중국 89056 12325 360 2931 49394 154066 2010-05 아시아 57.80 16.952005 2010 05
'''7.2.3. pivot table
df_pivot = df_filter.pivot_table(values = '관광', index = '년도', columns = '월')
df_pivot
'''
월 01 02 03 04 05 06 07 08 09 10 11 12
년도
2010 40425.0 60590.0 50330.0 84252.0 89056.0 87080.0 122432.0 142180.0 93545.0 107237.0 75686.0 58987.0
2011 55070.0 53863.0 72003.0 86397.0 85668.0 108060.0 170524.0 178937.0 144704.0 141824.0 113856.0 101605.0
2012 106606.0 74895.0 110965.0 166843.0 154841.0 179074.0 258907.0 268988.0 203857.0 204866.0 155503.0 148320.0
2013 148118.0 169395.0 182850.0 250549.0 196306.0 280319.0 417991.0 472005.0 353359.0 249850.0 208175.0 210950.0
2014 230706.0 219533.0 313400.0 429419.0 410971.0 429991.0 540683.0 588181.0 423133.0 459708.0 381118.0 345957.0
2015 327225.0 413096.0 386386.0 536428.0 517154.0 223101.0 172075.0 372990.0 453670.0 518651.0 409635.0 381722.0
2016 456636.0 424232.0 500018.0 601460.0 614636.0 671493.0 823016.0 747818.0 611538.0 588561.0 452082.0 456882.0
2017 489256.0 458952.0 263788.0 158784.0 172527.0 181507.0 207099.0 226153.0 229172.0 244541.0 223743.0 260983.0
2018 236825.0 237075.0 281020.0 283533.0 284317.0 303405.0 332657.0 360982.0 326438.0 382922.0 327664.0 345135.0
2019 320113.0 324291.0 369165.0 410542.0 413949.0 395196.0 439699.0 451570.0 432018.0 476460.0 426849.0 433577.0
2020 393336.0 49520.0 5040.0 522.0 179.0 NaN NaN NaN NaN NaN NaN NaN
'''7.2.4. 히트맵 시각화
7.2.4.1. seaborn
import matplotlib.pyplot as plt
import seaborn as snsplt.figure(figsize = (12 ,8))
sns.heatmap(df_pivot, annot = True, fmt = '.0f')
plt.show()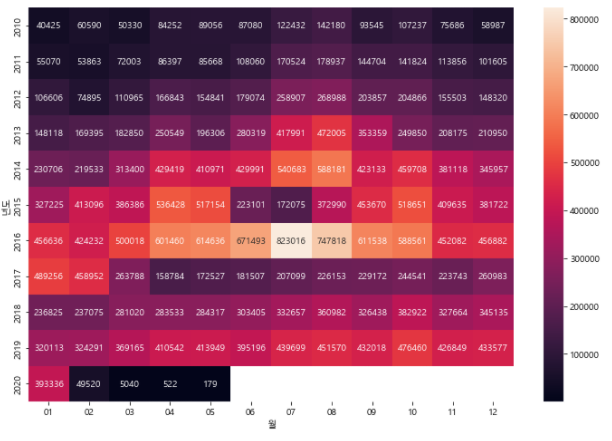
- 상위 5개국 시각화는 위와 같은 반복문으로 가능
# cntry_list
for cntry in cntry_list:
condition = df['국적'] == cntry
df_filter = df[condition]
df_pivot = df_filter.pivot_table(values = '관광',
index = '년도',
columns = '월')
plt.figure(figsize = (10, 8))
sns.heatmap(df_pivot, annot = True,
fmt = '.0f',
cmap = 'rocket_r') # r은 reverse
plt.title('{} 관광객 히트맵'.format(cntry))
plt.show()7.2.4.2. pyplot
- 예제 파일
flights = sns.load_dataset('flights')
flights.head()
'''
year month passengers
0 1949 Jan 112
1 1949 Feb 118
2 1949 Mar 132
3 1949 Apr 129
4 1949 May 121
'''- pivot
flights_pivot = flights.pivot_table(values = 'passengers', index = 'year',columns = 'month')
flights_pivot
'''
month Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec
year
1949 112 118 132 129 121 135 148 148 136 119 104 118
1950 115 126 141 135 125 149 170 170 158 133 114 140
1951 145 150 178 163 172 178 199 199 184 162 146 166
1952 171 180 193 181 183 218 230 242 209 191 172 194
1953 196 196 236 235 229 243 264 272 237 211 180 201
1954 204 188 235 227 234 264 302 293 259 229 203 229
1955 242 233 267 269 270 315 364 347 312 274 237 278
1956 284 277 317 313 318 374 413 405 355 306 271 306
1957 315 301 356 348 355 422 465 467 404 347 305 336
1958 340 318 362 348 363 435 491 505 404 359 310 337
1959 360 342 406 396 420 472 548 559 463 407 362 405
1960 417 391 419 461 472 535 622 606 508 461 390 432
'''- 시각화
plt.pcolor(flights_pivot, cmap = 'RdYlGn_r')
plt.colorbar()
plt.xticks(np.arange(0.5, len(flights_pivot.columns)), flights_pivot.columns)
plt.yticks(np.arange(0.5, len(flights_pivot.index)), flights_pivot.index)
plt.show()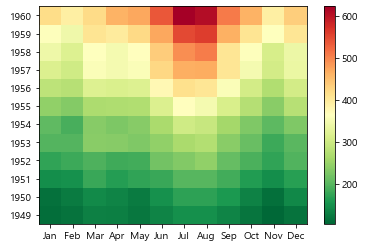
plt.figure(figsize = (12, 8))
sns.heatmap(flights_pivot,
annot = True,
fmt = 'd',
cmap = 'RdYlGn_r',
annot_kws = {'size': 10, 'color':'red'})
plt.title('Heatmap', fontsize = 10)
plt.show()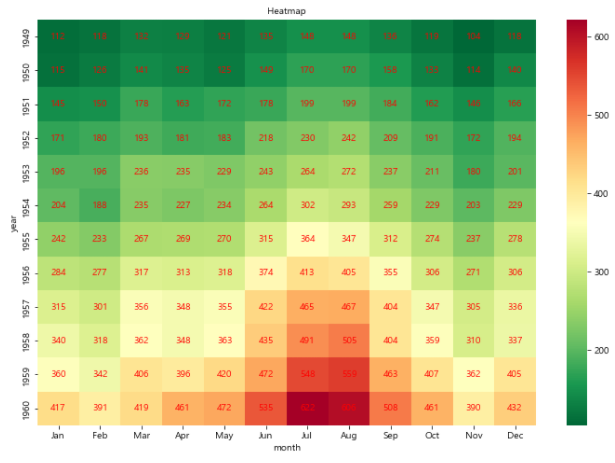
- 여러가지 시각화
penguins = sns.load_dataset('penguins')
sns.pairplot(penguins)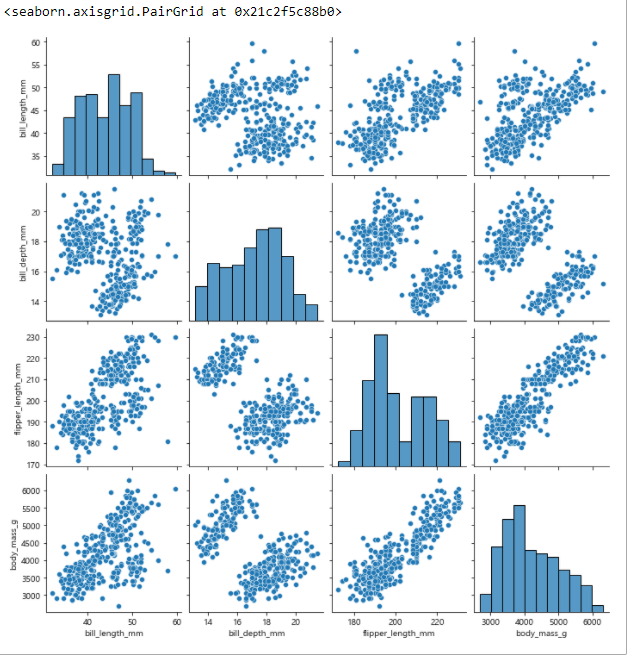
반응형
'Bigdata > Web Crawling' 카테고리의 다른 글
| __09.data_analyzing_visualizing_instagram (인스타그램 2편) (0) | 2022.01.17 |
|---|---|
| __08.data_analyzing_crawling_instagram (인스타그램 1편) (0) | 2022.01.17 |
| __06.data_analyzing_tourist_data (한국 관광객 추이 1편) (0) | 2022.01.14 |
| __05.data.analyzing_youtube_data_visualizing (유튜브 2편) (0) | 2022.01.14 |
| __04.data_analyzing_crawling_youtube_ranking (유튜브 1편) (0) | 2022.01.13 |
'Bigdata/Web Crawling' Related Articles
more


Comments