
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- matplotlib
- javascript
- 크롤링
- Scrum
- TypeScript
- algorithm
- keras
- AWS
- analyzing
- data analyze
- Method
- ECS
- pandas
- webcrawling
- 다나와
- tensorflow
- 프로젝트
- data
- adaptive life cycle
- python
- Crawling
- DANAWA
- 자바스크립트
- 애자일
- 판다스
- angular
- visualizing
- Project
- opencv
- Agile
Archives
- Today
- Total
LiJell's 성장기
Transfer Learning II 본문
반응형
2022.03.08 - [Bigdata/TensorFlow] - Tranfer_Learning
Tranfer_Learning
Dogs vs. Cats Google Colab 사용 Runtime에서 TPU 사용 추천 Dogs vs Cats dataset https://www.kaggle.com/c/dogs-vs-cats/data 25000 images (12500 cats and 12500 dogs) Create dataset Training: 1000 sam..
lime-jelly.tistory.com
- 작은 이미지 데이터셋에 딥러닝을 적용하는 일반적이고 효과적인 방법은 사전 훈련된 네트 워크를 사용
- 사전 훈련된 네트워크(pretrained network) - 일반적으로 대규모 이미지 분류 문제를 위 해 대량의 데이터셋에서 미리 훈련되어 저장된 네트워크
- ImageNet - 1400만개의 레이블된 이미지와 1000개의 클래스로 이루어 진 데이터셋
- VGG16 - Karen Simonyan & Andrew Zisserman이 2014년에 개발
- VGG16, ResNet, Inception, Inception-ResNet, Xception, ...
- 사전 훈련된 네트워크를 사용하는 방법
- 특성 추출(Feature Extraction)
- 미세 조정(Fine Tuning)
Feature Extraction
- 사전에 학습된 네트워크의 표현을 사용하여 새로운 샘플에서 흥미로운 특성을 추출
- 이런 특성을 사용하여 새로운 분류기를 처음부터 훈련
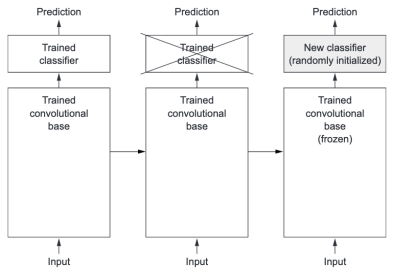
- 합성곱층(convolutional base)에 의해 학습된 표현이 더 일반적이어서 재사용이 가능
- Convnet의 특성맵은 사진에 대한 일반적인 콘셉트의 존재여부를 기록한 맵 → 주어진 컴퓨터 비젼 문제에 상 관없이 유용하게 사용 가능
- 분류기에서 학습한 표현은 모델이 훈련된 클래스 집합에 특화 → 전체 사진에 어떤 클래스가 존재할 확률에 관 한 정보만 가지고 있음
- Convnet에서 추출한 표현의 일반성(그리고 재사용성) 수준은 모델에 있는 층의 깊이에 달려 있음
- 모델의 하위층은 (에지, 색깔, 질감 등) 지역적이고 매우 일반적 특성맵을 추출
- 상위층은 ('강아지 눈'이나 '고양이 귀'처럼) 좀 더 추상적인 개념을 추출 → 새로운 데이터셋이 원본 모델이 훈련한 데이터셋과 많이 다르면 전체 convnet을 사용하는것 보다 모델의 하위 몇개 층만 특성추출에 사용 하는 것이 좋음

- keras.applications 모델에서 사용 가능한 이미지분류 모델
- Xception
- Inception V3
- ResNet50
- VGG16
- VGG19
- MobileNet
import os, shutil
original_db_dir = '/content/drive/MyDrive/tensflow/cats_and_dogs_small/train'
base_dir = '/content/drive/MyDrive/tensflow/cats_and_dogs_small'
train_dir = os.path.join(base_dir, 'train')
validation_dir = os.path.join(base_dir, 'validation')
test_dir = os.path.join(base_dir, 'test')
train_cats_dir = os.path.join(train_dir, 'cats')
train_dogs_dir = os.path.join(train_dir, 'dogs')
validation_cats_dir = os.path.join(validation_dir, 'cats')
validation_dogs_dir = os.path.join(validation_dir, 'dogs')
test_cats_dir = os.path.join(test_dir, 'cats')
test_dogs_dir = os.path.join(test_dir, 'dogs')import numpy as np
import tensorflow as tf
from tensorflow import kerasfrom tensorflow.keras.applications.vgg16 import VGG16
conv_base =VGG16(
weights='imagenet',
include_top=False,
input_shape=(150, 150, 3)
)
conv_base.summary()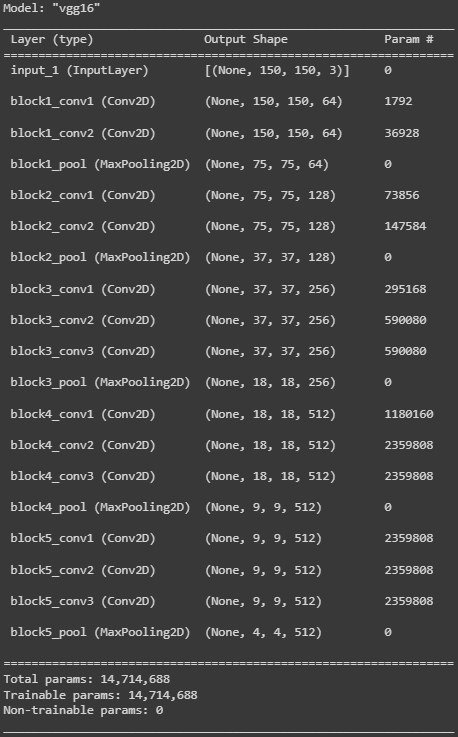
- 이 지점에서 두가지 방식이 가능
- 새로운 데이터셋에서 convnet을 실행하고 출력을 numpy배열로 디스크에 저장 → 이 데이터를 독립된 완전연결분류기에 입력으로 사용. 모든 입력 이미지에 대해 convnet 을 한번만 실행하면 되므로 빠르고 비용이 적게 듬. 하지만 이 기법에선 data augmentation을 사용할 수 없음
- 준비한 모델(conv_base)위에 Dense층을 쌓아 확장 → 입력 데이터에서 end-to-end 로 전체 모델을 실행. 모델에 노출된 모든 입력 이미지가 매번 convnet을 통과하므로 data augmentation 사용 가능. 하지만 그렇기 때문에 첫번째 보다 훨씬 많은 비용이 듬
Fast Feature Extraction without Data Augmentation
import os
import numpy as np
from tensorflow.keras.preprocessing.image import ImageDataGenerator
base_dir = '/content/drive/MyDrive/tensflow/cats_and_dogs_small'
train_dir = os.path.join(base_dir, 'train')
validation_dir = os.path.join(base_dir, 'validation')
test_dir = os.path.join(base_dir, 'test')
datagen = ImageDataGenerator(rescale=1./255)
batch_size = 20def extract_features(dir, sample_count):
features = np.zeros(shape=(sample_count, 4, 4, 512))
labels = np.zeros(shape=(sample_count))
generator = datagen.flow_from_directory(
dir,
target_size = (150,150),
batch_size = batch_size,
class_mode = 'binary'
)
i = 0
for inputs_batch, labels_batch in generator:
features_batch = conv_base.predict(inputs_batch)
features[i*batch_size: (i+1)*batch_size] = features_batch
labels[i*batch_size: (i+1)*batch_size] = labels_batch
i += 1
if i*batch_size >= sample_count:
break
return features, labels
train_features, train_labels = extract_features(train_dir, 2000)
validation_features, validation_labels = extract_features(validation_dir, 1000)
test_features, test_labels = extract_features(test_dir, 1000)train_features = np.reshape(train_features, (2000, 4*4*512))
validation_features = np.reshape(validation_features, (1000, 4*4*512))
test_features = np.reshape(test_features, (1000, 4*4*512))from tensorflow.keras.layers import Dense, Dropout
from tensorflow.keras import models
from tensorflow.keras import optimizers
model = models.Sequential()
model.add(Dense(256, activation='relu', input_dim=4*4*512))
model.add(Dropout(0.5))
model.add(Dense(1, activation='sigmoid'))
model.compile(optimizer=optimizers.RMSprop(lr=2e-5),
loss='binary_crossentropy',
metrics=['acc']
)
history = model.fit(
train_features,
train_labels,
epochs=30,
batch_size=20,
validation_data=(validation_features, validation_labels)
)
# 저장 위치는 Google Colab에 mount된 Google drive 경로에 저장
model.save('/content/drive/MyDrive/tensflow/cats_and_dogs_small_3.h5')import matplotlib.pyplot as plt
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(acc)+1)
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()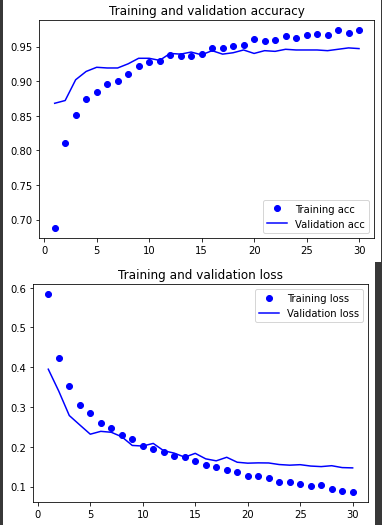
With Data Augmentation
from keras import models
from keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Dropout
model = models.Sequential()
model.add(conv_base)
model.add(Flatten())
model.add(Dense(256, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
model.summary()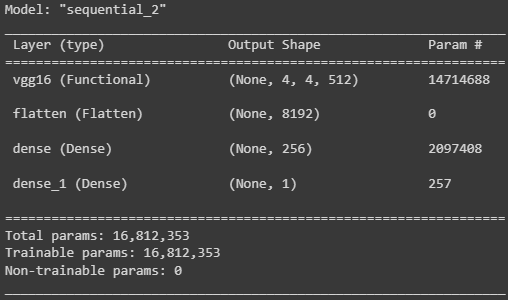
print ('conv_base를 동경하기 전 훈련되는 가중치의 수: ', len(model.trainable_weights))
conv_base.trainable = False
print ('conv_base를 동경한 후 훈련되는 가중치의 수: ', len(model.trainable_weights))
'''
conv_base를 동경하기 전 훈련되는 가중치의 수: 30
conv_base를 동경한 후 훈련되는 가중치의 수: 4
'''from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras import optimizers
train_datagen = ImageDataGenerator(
rescale=1./255,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest',
)
test_datagen = ImageDataGenerator(rescale=1./255) # 검증 데이터는 증식되면 안됨
train_generator = train_datagen.flow_from_directory(
train_dir,
target_size=(150,150),
batch_size=32,
class_mode='binary'
)validation_generator = test_datagen.flow_from_directory(
validation_dir,
target_size=(150,150),
batch_size=32,
class_mode='binary'
)
model.compile(loss='binary_crossentropy', optimizer=optimizers.RMSprop(lr=2e-5),metrics=['acc'])
history = model.fit_generator(
train_generator,
steps_per_epoch=50,
epochs=30,
validation_data=validation_generator,
validation_steps=50,
verbose=2,
)
model.save('/content/drive/MyDrive/tensflow/cats_and_dogs_small_5.h5')import matplotlib.pyplot as plt
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(acc)+1)
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()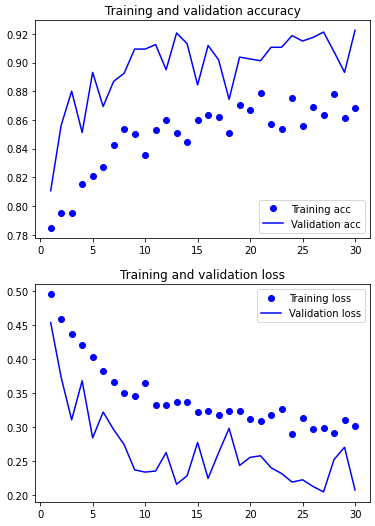
반응형
'Bigdata > TensorFlow' 카테고리의 다른 글
| RNN (0) | 2022.03.31 |
|---|---|
| Convnet Visualization (0) | 2022.03.14 |
| Tranfer_Learning (0) | 2022.03.08 |
| CNN for MNIST (0) | 2022.03.07 |
| Convolution Neural Network (CNN) (0) | 2022.03.07 |
'Bigdata/TensorFlow' Related Articles
more




Comments