
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- data
- webcrawling
- visualizing
- data analyze
- angular
- AWS
- Method
- adaptive life cycle
- TypeScript
- 프로젝트
- 다나와
- analyzing
- tensorflow
- 자바스크립트
- keras
- Scrum
- javascript
- python
- 판다스
- opencv
- DANAWA
- Project
- Crawling
- algorithm
- Agile
- ECS
- matplotlib
- 크롤링
- pandas
- 애자일
Archives
- Today
- Total
LiJell's 성장기
__11.data_analyzing_Starbucks_crawling (스타벅스 1편) 본문
Bigdata/Web Crawling
__11.data_analyzing_Starbucks_crawling (스타벅스 1편)
All_is_LiJell 2022. 1. 19. 18:08반응형
- 스타벅스 2편 전처리: https://lime-jelly.tistory.com/52
- 스타벅스 3편 시각화: https://lime-jelly.tistory.com/53
__12.data.analyzing_Starbucks_data_preprocessing (스타벅스 2편)
스타벅스 크롤링 1편: https://lime-jelly.tistory.com/51 스타벅스 시각화 3편: https://lime-jelly.tistory.com/53 12. Starbucks data preprocessing (스타벅스 데이터 전처리) 서울 열린데이터 광장 OPEN API..
lime-jelly.tistory.com
__13.data.analyzing_Starbucks_data_visualizing
스타벅스 1편 크롤링: https://lime-jelly.tistory.com/51 스타벅스 2편 전처리: https://lime-jelly.tistory.com/52 13. Starbucks data visualizing (스타벅스 데이터 비주얼라이징) 13.1 스타벅스 매장분포 시..
lime-jelly.tistory.com
11. Starbucks Crawling (스타벅스 크롤링)
11. 1 크롤링을 이용한 서울시 스타벅스 매장 목록 데이터 생성
11.1.1. 라이브러리 가져오기
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from bs4 import BeautifulSoup
from selenium.webdriver.common.by import By
import pandas as pd
import numpy as np
import time11.1.2. 지역별 매장 검색 화면 접속
- 크롤링에 대한 이해가 없다면 data_analyzing 포스팅들을 확인하세요
ser = Service('../chromedriver/chromedriver.exe')
driver = webdriver.Chrome(service = ser)
url = 'https://www.starbucks.co.kr/'
driver.get(url)- 먼저 스타벅스 사이트로 이동 후, 아래 화면으로 이동해 주세요. (지역 검색!)
- 또는 url을 아예 해당 위치에서 복사입력해도 좋습니다.

11.1.3. 서울 버튼 클릭과 전체 버튼 클릭
- 이제부터 우린 코딩으로 합니다.
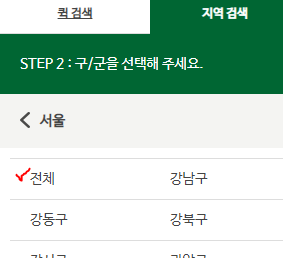
- 서울버튼 클릭
# 웹페이지 관리자 모드에서 상단에 표시된 것을 눌러 원하는 곳의 태그를 확인
# 우클릭 > Copy > Copy selector > 붙여넣기
# 아래와 같은 경로를 받을 수 있습니다.
seoul_btn = '#container > div > form > fieldset > div > section > article.find_store_cont > article > article:nth-child(4) > div.loca_step1 > div.loca_step1_cont > ul > li:nth-child(1) > a'
driver.find_element(By.CSS_SELECTOR, seoul_btn).click()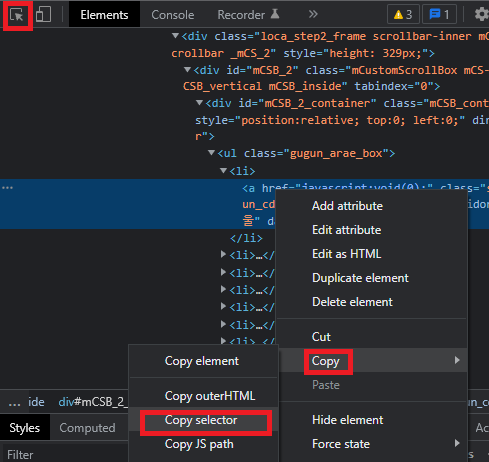
- 동일한 방법으로 전체버튼 클릭
all_btn = '#mCSB_2_container > ul > li:nth-child(1) > a'
driver.find_element(By.CSS_SELECTOR, all_btn).click()
time.sleep(3) # 오류방지11.1.4. HTML 받아오기
- parser 만들기
html = driver.page_source
soup= BeautifulSoup(html, 'html.parser')
soup.head()- 원하는 HTML 태그 찾기
- 매장명, 위도, 경도, 매장 타입, 주소, 전화번호
starbucks_soup_list = soup.select('#mCSB_3 li.quickResultLstCon')
len(starbucks_soup_list)
'''
568
'''starbucks_store = starbucks_soup_list[0]
starbucks_store
'''
<li class="quickResultLstCon" data-code="3762" data-hlytag="null" data-index="0" data-lat="37.501087" data-long="127.043069" data-name="역삼아레나빌딩" data-storecd="1509" style="background:#fff"> <strong data-my_siren_order_store_yn="N" data-name="역삼아레나빌딩" data-store="1509" data-yn="N">역삼아레나빌딩 </strong> <p class="result_details">서울특별시 강남구 언주로 425 (역삼동)<br/>1522-3232</p> <i class="pin_general">리저브 매장 2번</i></li>
'''11.1.5. 원하는 데이터 뽑기
name = starbucks_store.select('strong')[0].text.strip()
name
lat = starbucks_store['data-lat'].strip()
lng = starbucks_store['data-long'].strip()
# store_type = starbucks_store.select('i')[0]['class'][0].split('_')[1]
store_type = starbucks_store.select('i')[0]['class'][0][4:]
print(type(store_type))
store_type
'''
<class 'str'>
'general'
'''# address = starbucks_store.select('#mCSB_3 p.result_details')[0].text
# len(address)
# address[:-9].strip()
# 아래와 같이 하는 이유는 정보의 길이가 다르거나 정보가 바뀔 경우를 대비 호환성이 좋음
address = str(starbucks_store.select('#mCSB_3 p.result_details')[0]).split('<br/>')[0].split('>')[1]
address
'''
'서울특별시 강남구 언주로 425 (역삼동)'
'''tel = str(starbucks_store.select('#mCSB_3 p.result_details')[0]).split('<br/>')[1].split('<')[0]
print(type(phone_num))
tel
'''
<class 'str'>
'1522-3232'
'''- 합치기
starbucks_list = []
for item in starbucks_soup_list:
name = item.select('strong')[0].text.strip()
lat = item['data-lat'].strip()
lng = item['data-long'].strip()
store_type = item.select('i')[0]['class'][0][4:]
address = str(item.select('#mCSB_3 p.result_details')[0]).split('<br/>')[0].split('>')[1]
tel = str(item.select('#mCSB_3 p.result_details')[0]).split('<br/>')[1].split('<')[0]
starbucks_list.append([name, lat, lng, store_type, address, tel])
starbucks_list11.1.6. 데이터프레임 생성 및 저장
columns = ['매장명','위도','경도','매장타입','주소','전화번호']
seoul_starbucks_df = pd.DataFrame(starbucks_list, columns = columns)
seoul_starbucks_df.head()
seoul_starbucks_df.info()
'''
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 568 entries, 0 to 567
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 매장명 568 non-null object
1 위도 568 non-null object
2 경도 568 non-null object
3 매장타입 568 non-null object
4 주소 568 non-null object
5 전화번호 568 non-null object
dtypes: object(6)
memory usage: 26.8+ KB
'''- 저장
seoul_starbucks_df.to_excel('./files/seoul_starbucks_list_class.xlsx', index = False)반응형
'Bigdata > Web Crawling' 카테고리의 다른 글
| __13.data.analyzing_Starbucks_data_visualizing (스타벅스 3편) (0) | 2022.01.20 |
|---|---|
| __12.data.analyzing_Starbucks_data_preprocessing (스타벅스 2편) (0) | 2022.01.20 |
| __10.data.analyzing_map_instagram(인스타그램 3편) (2) | 2022.01.18 |
| __09.data_analyzing_visualizing_instagram (인스타그램 2편) (0) | 2022.01.17 |
| __08.data_analyzing_crawling_instagram (인스타그램 1편) (0) | 2022.01.17 |
'Bigdata/Web Crawling' Related Articles
more



Comments