
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- pandas
- javascript
- tensorflow
- data analyze
- adaptive life cycle
- 판다스
- Scrum
- Project
- 애자일
- DANAWA
- opencv
- algorithm
- angular
- python
- keras
- 프로젝트
- TypeScript
- 자바스크립트
- matplotlib
- 다나와
- Crawling
- data
- Agile
- ECS
- webcrawling
- visualizing
- analyzing
- Method
- 크롤링
- AWS
Archives
- Today
- Total
LiJell's 성장기
__01.data_analyzing_pandas 본문
반응형
"""
Created on Wed Jan 12 2021
@author: hanju
"""
1. 데이터 불러오기
- file download: https://github.com/Play-with-data/datasalon
- 02_개정판을 이용
import pandas as pd
import numpy as np- csv file 불러오기
fish = pd.read_csv('https://bit.ly/fish_csv',
encoding = 'utf-8') # 한글 오류 있으면 encoding = 'euc-kr'
fish
'''
Species Weight Length Diagonal Height Width
0 Bream 242.0 25.4 30.0 11.5200 4.0200
1 Bream 290.0 26.3 31.2 12.4800 4.3056
2 Bream 340.0 26.5 31.1 12.3778 4.6961
3 Bream 363.0 29.0 33.5 12.7300 4.4555
4 Bream 430.0 29.0 34.0 12.4440 5.1340
... ... ... ... ... ... ...
154 Smelt 12.2 12.2 13.4 2.0904 1.3936
155 Smelt 13.4 12.4 13.5 2.4300 1.2690
156 Smelt 12.2 13.0 13.8 2.2770 1.2558
157 Smelt 19.7 14.3 15.2 2.8728 2.0672
158 Smelt 19.9 15.0 16.2 2.9322 1.8792
159 rows × 6 columns
'''- excel 불러오기
sample_1 = pd.read_excel('./files/sample_1.xlsx',
header = 1,
usecols= 'A:C',
skipfooter = 2,
)
- 정보보기
sample_1
'''
국적코드 성별 입국객수
0 A01 남성 106320
1 A01 여성 191436
2 A31 남성 319
3 A31 여성 42
4 A18 남성 158912
5 A18 여성 232943
'''
print(sample_1.head()) # row 5개 data 나옴 위에서부터
'''
국적코드 성별 입국객수
0 A01 남성 106320
1 A01 여성 191436
2 A31 남성 319
3 A31 여성 42
4 A18 남성 158912
'''
print(sample_1.tail()) # 아래부터
'''
국적코드 성별 입국객수
1 A01 여성 191436
2 A31 남성 319
3 A31 여성 42
4 A18 남성 158912
5 A18 여성 232943
'''
print(sample_1.info())
'''
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 6 entries, 0 to 5
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 국적코드 6 non-null object
1 성별 6 non-null object
2 입국객수 6 non-null int64
dtypes: int64(1), object(2)
memory usage: 272.0+ bytes
None
'''
sample_1.dtypes
'''
국적코드 object
성별 object
입국객수 int64
dtype: object
'''
sample_1.describe() # summary statics 입국객수만 int라서 입국객수만 나옴
# 연속형 자료에 대한 통계 자료
'''
입국객수
count 6.000000
mean 114995.333333
std 98105.752006
min 42.000000
25% 26819.250000
50% 132616.000000
75% 183305.000000
max 232943.000000
'''2. 데이터 선택
sample_1
'''
국적코드 성별 입국객수
0 A01 남성 106320
1 A01 여성 191436
2 A31 남성 319
3 A31 여성 42
4 A18 남성 158912
5 A18 여성 232943
'''
sample_1['입국객수']
'''
0 106320
1 191436
2 319
3 42
4 158912
5 232943
Name: 입국객수, dtype: int64
'''
sample_1[['국적코드', '성별']]
'''
국적코드 성별
0 A01 남성
1 A01 여성
2 A31 남성
3 A31 여성
4 A18 남성
5 A18 여성
'''
sample_1['기준년월'] = '2022-01' # 없는거 넣어주기
sample_1
'''
국적코드 성별 입국객수 기준년월
0 A01 남성 106320 2022-01
1 A01 여성 191436 2022-01
2 A31 남성 319 2022-01
3 A31 여성 42 2022-01
4 A18 남성 158912 2022-01
5 A18 여성 232943 2022-01
'''
조건으로 데이터 선택하기
- ==
sample_1[sample_1['성별'] == '남성']
'''
국적코드 성별 입국객수 기준년월
0 A01 남성 106320 2022-01
2 A31 남성 319 2022-01
4 A18 남성 158912 2022-01
'''
condition = (sample_1['성별'] == '남성')
print(condition)
print(~condition)
sample_1[condition]
'''
0 True
1 False
2 True
3 False
4 True
5 False
Name: 성별, dtype: bool
0 False
1 True
2 False
3 True
4 False
5 True
Name: 성별, dtype: bool
국적코드 성별 입국객수 기준년월
0 A01 남성 106320 2022-01
2 A31 남성 319 2022-01
4 A18 남성 158912 2022-01
'''- 부등호
condition = (sample_1['입국객수'] >= 150000)
print(condition)
print(~condition) # 컨디션 반대로 할 때 '~' not 을 쓴다
sample_1[condition]
'''
0 False
1 True
2 False
3 False
4 True
5 True
Name: 입국객수, dtype: bool
0 True
1 False
2 True
3 True
4 False
5 False
Name: 입국객수, dtype: bool
국적코드 성별 입국객수 기준년월
1 A01 여성 191436 2022-01
4 A18 남성 158912 2022-01
5 A18 여성 232943 2022-01
'''- and(&)
condition = (sample_1['성별'] == '남성') & (sample_1['입국객수'] >=150000)
print(condition)
'''
0 False
1 False
2 False
3 False
4 True
5 False
dtype: bool
'''
condition_1 = (sample_1['성별'] == '남성')
condition_2 = (sample_1['입국객수'] >= 150000)
print(condition_1)
print(condition_2)
print(condition_1 & condition_2)
conditions = condition_1 & condition_2
sample_1[conditions]
'''
0 True
1 False
2 True
3 False
4 True
5 False
Name: 성별, dtype: bool
0 False
1 True
2 False
3 False
4 True
5 True
Name: 입국객수, dtype: bool
0 False
1 False
2 False
3 False
4 True
5 False
dtype: bool
국적코드 성별 입국객수 기준년월
4 A18 남성 158912 2022-01
'''
- or(|)
conditions = (sample_1['국적코드'] == 'A01') | (sample_1['국적코드'] == 'A18')
print(conditions)
'''
0 True
1 True
2 False
3 False
4 True
5 True
Name: 국적코드, dtype: bool
'''- 조건이 많을 때
conditions = (sample_1['국적코드'].isin(['A01' , 'A31'])) # or 로 연산함
print(conditions)
'''
0 True
1 True
2 True
3 True
4 False
5 False
Name: 국적코드, dtype: bool
'''- loc로 탐색하기
sample_1.loc[1:3, '성별'] # lioc index는 3을 포함하지 않음
'''
1 여성
2 남성
3 여성
Name: 성별, dtype: object
'''3. 데이터 통합 (merge)
- merge는 column을 붙여준다( 옆으로)
code_master = pd.read_excel('./files/sample_codemaster.xlsx', header= 0, usecols= 'A:B', skipfooter = 0)
code_master
'''
국적코드 국적명
0 A01 일본
1 A02 대만
2 A03 홍콩
3 A18 중국
4 A19 이란
5 A22 우즈베키스탄
6 A23 카자흐스탄
7 A99 아시아 기타
'''sample_1.head()
'''
국적코드 성별 입국객수 기준년월
0 A01 남성 106320 2022-01
1 A01 여성 191436 2022-01
2 A31 남성 319 2022-01
3 A31 여성 42 2022-01
4 A18 남성 158912 2022-01
'''
sample_1_code = pd.merge(left = sample_1,
right = code_master,
how = 'left', #왼쪽을 기준으로 붙이겠다
left_on = '국적코드',
right_on = '국적코드')
sample_1_code
'''
국적코드 성별 입국객수 기준년월 국적명
0 A01 남성 106320 2022-01 일본
1 A01 여성 191436 2022-01 일본
2 A31 남성 319 2022-01 NaN
3 A31 여성 42 2022-01 NaN
4 A18 남성 158912 2022-01 중국
5 A18 여성 232943 2022-01 중국
'''- how 설정에 따른 변화
sample_1_code = pd.merge(left = sample_1,
right = code_master,
how = 'inner', #매칭이 안되는건 빠진다 # 교집합
left_on = '국적코드',
right_on = '국적코드')
sample_1_code
'''
국적코드 성별 입국객수 기준년월 국적명
0 A01 남성 106320 2022-01 일본
1 A01 여성 191436 2022-01 일본
2 A18 남성 158912 2022-01 중국
3 A18 여성 232943 2022-01 중국
'''
sample_1_code = pd.merge(left = sample_1,
right = code_master,
how = 'outer', #매칭이 안되는건 빠진다 # 합집합
left_on = '국적코드',
right_on = '국적코드')
sample_1_code
'''
국적코드 성별 입국객수 기준년월 국적명
0 A01 남성 106320.0 2022-01 일본
1 A01 여성 191436.0 2022-01 일본
2 A31 남성 319.0 2022-01 NaN
3 A31 여성 42.0 2022-01 NaN
4 A18 남성 158912.0 2022-01 중국
5 A18 여성 232943.0 2022-01 중국
6 A02 NaN NaN NaN 대만
7 A03 NaN NaN NaN 홍콩
8 A19 NaN NaN NaN 이란
9 A22 NaN NaN NaN 우즈베키스탄
10 A23 NaN NaN NaN 카자흐스탄
11 A99 NaN NaN NaN 아시아 기타
'''
sample_2 = pd.read_excel('./files/sample_2.xlsx',
header =1,
skipfooter = 2,
usecols = 'A:C')
sample_2['기준년월'] = '2022-02'
sample_2_code = pd.merge(left = sample_2,
right = code_master,
how = 'left',
on = '국적코드')
sample_2_code
'''
국적코드 성별 입국객수 기준년월 국적명
0 A01 남성 92556 2022-02 일본
1 A01 여성 163737 2022-02 일본
2 A18 남성 155540 2022-02 중국
3 A18 여성 249023 2022-02 중국
'''4. 데이터 통합 (append)
- append는 row를 붙여준다. (세로)
sample = sample_1_code.append(sample_2_code,
ignore_index = False) # index 그대로 합쳐짐
sample
'''
국적코드 성별 입국객수 기준년월 국적명
0 A01 남성 106320 2022-01 일본
1 A01 여성 191436 2022-01 일본
2 A31 남성 319 2022-01 NaN
3 A31 여성 42 2022-01 NaN
4 A18 남성 158912 2022-01 중국
5 A18 여성 232943 2022-01 중국
0 A01 남성 92556 2022-02 일본
1 A01 여성 163737 2022-02 일본
2 A18 남성 155540 2022-02 중국
3 A18 여성 249023 2022-02 중국
'''
sample = sample_1_code.append(sample_2_code,
ignore_index = True) # 인덱스 순서대로 다시 번호
sample
'''
국적코드 성별 입국객수 기준년월 국적명
0 A01 남성 106320 2022-01 일본
1 A01 여성 191436 2022-01 일본
2 A31 남성 319 2022-01 NaN
3 A31 여성 42 2022-01 NaN
4 A18 남성 158912 2022-01 중국
5 A18 여성 232943 2022-01 중국
6 A01 남성 92556 2022-02 일본
7 A01 여성 163737 2022-02 일본
8 A18 남성 155540 2022-02 중국
9 A18 여성 249023 2022-02 중국
'''
5. 데이터 통합 (concat)
- concat은 한번에 여러 데이터를 합치기 용이하며, axis 값에 따라 rows 또는 columns을 합친다.
sample_concat = pd.concat([sample_1_code, sample_2_code], # concat이 한번에 넣기 편함
ignore_index = True,
axis = 0)
sample_concat
'''
국적코드 성별 입국객수 기준년월 국적명
0 A01 남성 106320 2022-01 일본
1 A01 여성 191436 2022-01 일본
2 A31 남성 319 2022-01 NaN
3 A31 여성 42 2022-01 NaN
4 A18 남성 158912 2022-01 중국
5 A18 여성 232943 2022-01 중국
6 A01 남성 92556 2022-02 일본
7 A01 여성 163737 2022-02 일본
8 A18 남성 155540 2022-02 중국
9 A18 여성 249023 2022-02 중국
'''6. 데이터 저장 ( excel )
sample.to_excel('./files/sample_class.xlsx',
index = False, # 인덱스가 불필요 하기에
na_rep = 'NaN', sheet_name = 'mysheet') #represent 빈칸을 NaN으로 넣기 위해
- 하나의 파일에 여러가지 sheet을 저장하는 방법
with pd.ExcelWriter('./files/multiple_sheet.xlsx') as writer:
sample.to_excel(writer, sheet_name = 'my_sheet1')
sample.to_excel(writer, sheet_name = 'my_sheet2',
# 다른 파일에 저장하고싶으면 파일 이름을 바꿔서
index = False,
na_rep= 'NaN')7. 피벗 테이블 (pivot table)
sample_pivot = sample.pivot_table(
values = '입국객수',
index = '국적명',
columns = '기준년월',
aggfunc = 'mean')
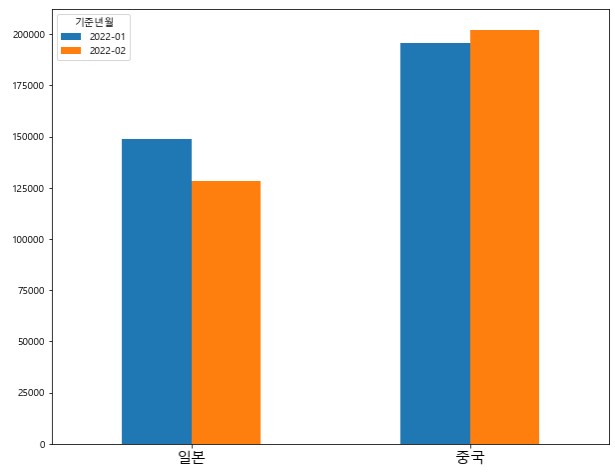
sample_pivot
'''
기준년월 2022-01 2022-02
국적명
일본 148878.0 128146.5
중국 195927.5 202281.5
'''8. 가시화 (visualization)
import matplotlib.pyplot as plt
plt.rc('font', family = "Malgun Gothic")
plt.rcParams['axes.unicode_minus'] = False
# sample
# type(sample_pivot)
sample_pivot.plot(kind= 'bar',
figsize = (10, 8),
rot =0)
plt.xlabel("")
plt.xticks(size = 15)
plt.yticks(size = 10)
plt.show()
9. groupby
sample.groupby('성별')['입국객수'].mean()
'''
성별
남성 102729.4
여성 167436.2
Name: 입국객수, dtype: float64
'''
sample['입국객수'].mean()
'''
135082.8
'''반응형
'Bigdata > Web Crawling' 카테고리의 다른 글
| __06.data_analyzing_tourist_data (한국 관광객 추이 1편) (0) | 2022.01.14 |
|---|---|
| __05.data.analyzing_youtube_data_visualizing (유튜브 2편) (0) | 2022.01.14 |
| __04.data_analyzing_crawling_youtube_ranking (유튜브 1편) (0) | 2022.01.13 |
| __03.data_analyzing_crawling_melon_bugs_genie (멜론, 벅스, 지니) (3) | 2022.01.13 |
| __02.data_analyzing_crawling (크롤링) (0) | 2022.01.13 |
'Bigdata/Web Crawling' Related Articles
more


Comments